
AI Has Entered the Villa.
Skill stopped predicting risk this year. Here’s what that does to your detections and where your playbook quietly breaks.

I GOT A TEXT!!! And unlike Love Island, this one actually made me nervous. Anthropic just dropped a breakdown of 832 accounts they banned for malicious cyber activity in a single year mapping what those actors actually did with AI onto MITRE ATT&CK. It’s a real dataset, not a fear pitch, but one number stopped me mid-scroll.
The share of actors scoring medium-risk or higher on Anthropic’s enablement scale climbed from roughly 33% to 56% in under a year. A 1.7x jump. The most bothersome part? It happened without the actors getting any more skilled. Technical sophistication was your type on paper; looks great, predicts almost nothing about the actual connection (r = 0.28), as did the breadth of techniques an actor used (r = 0.27). So did which interface they came through. The thing that used to tell you how worried to be, “Is this a sophisticated adversary?”, doesn’t really apply anymore.
That’s the real story and I don’t say it to be inflammatory. It’s a tooling problem. The mental model most of us use to triage threats assumes risk tracks skill. When skill stops tracking risk, the model breaks and a lot of our playbooks were built on top of that model.
So let’s start with something productive: mapping your existing detections to what these actors are actually doing (most of it you likely already cover) and then we’ll talk about the part you don’t.

What’s mappable
A web shell is still a web shell. None of these techniques are new. Your existing ATT&CK-aligned detections fire on the artifact and the action regardless of whether a human or a model produced them. The report logged 13,873 observations across 482 sub-techniques within14 tactics, each having a MITRE ID and likely a rule in your library.
I’ve split the coverage into two tiers because that split is the argument. Tier 1 is the high-prevalence preparatory work that dominates the dataset and Tier 2 is the smaller, post-compromise cluster where the highest-risk actors actually start to separate themselves.
Tier 1 — Preparatory and pre-intrusion
Can you say volume? The single most common technique family was T1587.001 (Malware Development), used by 560 of 832 actors. Most AI-enabled activity today is actors building offensive tooling before they engage, then making it harder to detect.

What AI changes in Tier 1: mostly volume and variety. One actor can now generate dozens of obfuscation variants for the cost of a few prompts, so signature coverage decays faster than it used to. But your behavioral detections hold and so do your runbooks. If you cover this tier well, you’re in good shape against the majority of the population in the dataset.
Tier 2 — Post-compromise and hands-on-keyboard (or: After Casa Amor)
This tier is a little rarer; lateral movement showed up in just 0.7% of all observations, but the risk is more concentrated. The 54 actors who used AI for lateral movement averaged a risk score about 10 points above the mean, the strongest single predictor of a high-risk actor in the entire study. The techniques below were three to five times more common among the highest-risk cohort than the general population.
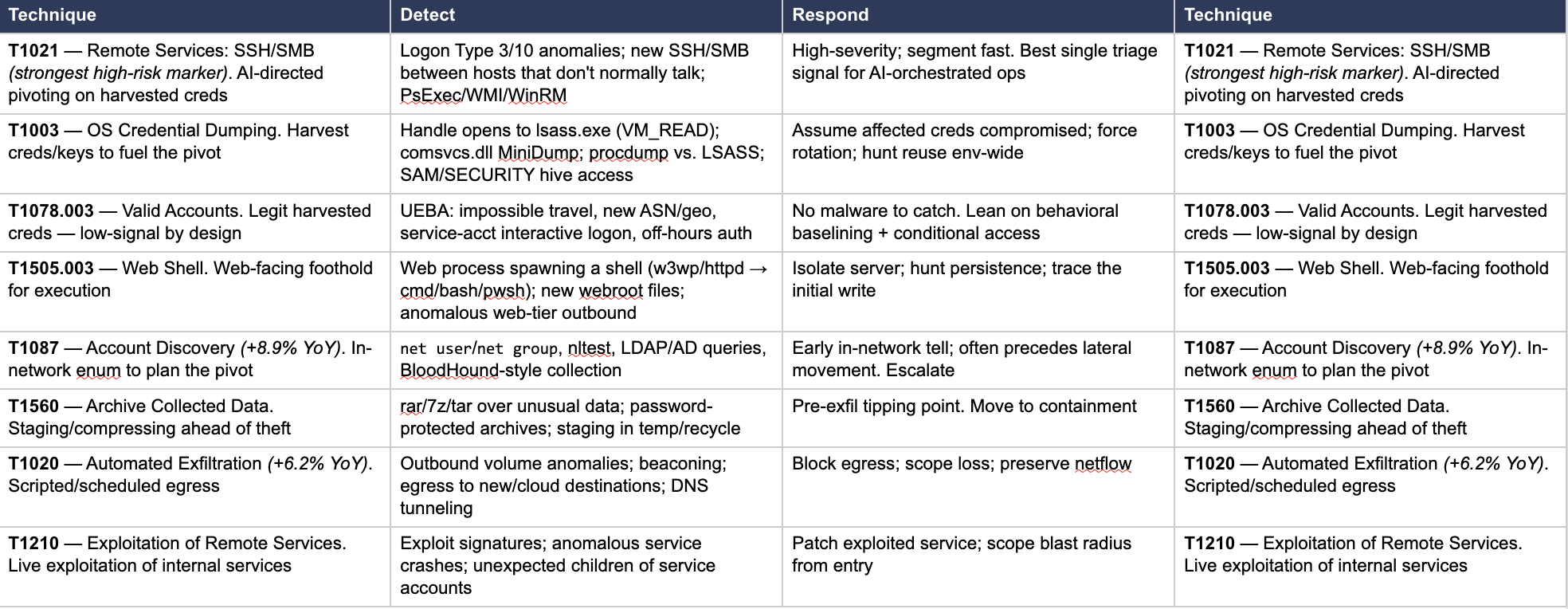
Notice the two techniques flagged with year-over-year growth. T1087 and T1020 both presuppose that the actor is already inside the network. The activity that grew over the study window wasn’t more tool-building, it was actually more in-network work. What that really means to me: the population isn’t just getting bigger, it’s actually drifting toward the riskier end of the kill chain.
What AI changes in Tier 2: this is where your runbook’s hidden assumption breaks. It’s worth being precise about what breaks, too, because it isn’t the detections.
The cadence is what fails. Now, you’re sending three home.
Can I pull your playbooks for a chat? Every response playbook you’ve ever written silently assumes a human operator’s tempo between these steps. Recon takes a while. There’s dwell time before lateral movement. Discovery, credential access, and the pivot are separate phases with gaps between them. THOSE gaps are what your alert triage, analyst SOPs, and SOAR playbooks were designed around.
Now picture those phases collapsed into one uninterrupted sequence, executed at machine speed, by something that doesn’t get tired, doesn’t context-switch, doesn’t wait for a second analyst to confirm before moving, and doesn’t need to recouple between phases. The individual detections still fire. T1003 fires, T1021 fires, T1087 fires, but they fire concurrently or out of the order your triage expects. Now your mean-time-to-respond is suddenly racing an adversary that doesn’t need to stand up and stretch their legs.
That’s the honest version of what changes. Not “AI invents undetectable attacks” (at least not yet) it’s that the spacing between known techniques is no longer guaranteed. I want to be careful with that “yet,” though. I’m describing what the dataset shows today: known TTPs, executed faster and I genuinely don’t know if that holds. If a model crosses some capability threshold we haven’t hit, call it AGI, call it whatever, there’s no law of nature that says it stays inside the existing technique map or even inside human-plausible speed. The honest position is that I’m bounding a present-tense problem, not predicting the ceiling.
Soul Ties Is Crazy…So is Lateral Movement at Machine Speed: Where the map runs out.
Something else the report is very transparent about: you can map every individual action one of these actors takes (Anthropic did exactly that, with 13,873 observations, every one with a MITRE ID) and mapping all of it still doesn’t capture what made the highest-risk actor in the dataset dangerous.
Consider the espionage campaign Anthropic disrupted in November 2025, labeled GTG-1002. Maximum possible risk score: 100. Number of techniques: about 30 across 13 tactics which is comparable to plenty of medium-risk actors. The median actor in the whole study used 16 techniques, and some low-risk actors used more than 30. By every metric we normally reach for, things like technique count, tactic breadth, interface, assessed skill, GTG-1002 actually looks like Rob standing at the firepit in his overalls, unremarkable.
But what made it the most dangerous actor observed wasn’t any technique, it was the scaffolding. The actor wired an AI agent into a Kali box with offensive tooling exposed as MCP servers and it wasn’t asking for advice, it was standing on business; scanning, pivoting, deciding what to probe next all on its own. The AI scanned, found internal services, exploited an SSRF flaw to pivot inward, harvested SSH keys and cloud credentials and moved laterally. All the while it was making its own tactical calls about what to probe next, with the human only stepping in for the consequential decisions.
Autonomous chaining of the kill chain. Real-time pivot decisions. AI-directed execution with no human in the loop between steps. None of these has an MITRE ATT&CK ID. There’s no technique to map a detection to because the dangerous thing isn’t a technique, it’s the orchestration between techniques. The taxonomy our entire shared threat vocabulary is built on describes the moves but it essentially has no vocabulary for the player.
This is why it can feel unwinnable. You can have perfect coverage of all 482 techniques and still be blind to the one variable that best predicts catastrophic risk because that variable doesn’t exist in your framework yet.
Is all this really unwinnable? Are we defenders doomed? Are we Kordell standing at an empty door?
It feels that way some days, and I’d rather say that out loud than pretend otherwise. But “unwinnable” is the wrong frame, IMO.
The wrong work is mapping more rules to a frozen taxonomy. If the differentiator has moved to the orchestration layer, adding the 483rd technique mapping doesn’t help you. The math only changes if your detection thinking moves up a level too:
Detect tempo, not just technique. A sequence of individually-benign-looking actions executing faster than a human plausibly could is itself the signal. Machine-speed sequencing across discovery → cred access → lateral movement is a behavioral fingerprint even when each step looks normal in isolation. This is where UEBA and sequence-aware detection come in clutch.
Watch the orchestration interfaces. Tool-augmented operations through MCP-style servers and agentic harnesses are a new and observable surface. They don’t map to MITRE today but they leave traces.
Compress vuln-to-patch. If attackers can autonomously find and chain exploitation at speed, your tolerance for known-unpatched systems has to drop accordingly. The transitional period rewards whoever shrinks that window fastest.
Push on the framework. Anthropic is in active conversations with MITRE about adding cross-cutting categories for agentic, autonomous, decision-making behaviors. That vocabulary is coming. The teams that have already started detecting at the behavioral layer will adopt it fastest.

Now, I also have to mention that there’s a genuinely defensible reason for optimism about this new bombshell. The same capabilities that let a low-skill actor command an expert-level harness also let defenders find bugs before code ships, triage at machine speed, and close the patch gap. The asymmetry that’s hurting us right now isn’t permanent, it’s a function of attackers adopting the tooling faster than defenders have and that gap is one we control.
But I want to keep the same honesty I used a few paragraphs up. That optimism is scoped to the problem I’ve actually described: known techniques, executed faster by a population drifting up the kill chain. It’s a real edge against a real, present-tense threat and we should take it. What it isn’t is a guarantee about the thing I admitted I can’t see. If capability jumps somewhere we’re not expecting, “defenders have the same tools” stops being reassurance, because both sides would be improvising against a map that no longer describes the territory. I’d rather hand you a defensible reason for optimism about today than a fragile promise about a future none of us can map yet.
So here’s where I land. The battle isn’t unwinnable but the old way of fighting it is. Map your detections to the techniques (yes, genuinely, all of them, it’s worth doing), then accept that the map ends where the orchestration begins, and start building for the territory past the edge. And hold that posture loosely, because the edge moves. The teams that win the next few years won’t be the ones with the most complete rule library; they’ll be the ones who stayed honest about what their map couldn’t see yet, and built the muscle to notice when it changed.
Source: Anthropic, “Mapping AI-enabled cyber threats: Insights from the LLM ATT&CK Navigator,” June 2026
 | A guest post by
|